지난글 : 에피소드 리스트 생성
지난 글에서 여러 states들을 하나의 튜플로 묶어 저장하고 스텝에 따른 state 시퀀스를 episode list [] 에 append하여 차곡차곡 쌓아 나가는 것을 공부하였다. (에피소드 리스트 생성)
[MC-블랙잭] Monte Carlo에서 Q-table 어떻게 만들어? (1) 튜플
참고하기 위한 코드와 글들을 찾으며 공부한 내용을 기록하였다. 클래스를 활용한 코드들도 있고 그렇지 않은 코드들도 있었다. 코드진행을 이해하기 위해서 파이썬에서의 클래스 문법을 공부
needs-searcher.tistory.com
Q-table 만들기
[문제점]
가장 중요한 것은 Q-table만들기였는데 아래와 같은 문제점이 있었다.

[해결방법 : dictionary 자료형]
즉, 수많은 순서를 매기기 어려운 state들을 Qtable의 행으로 넣어야 하는데 이는 Qtable을 dictionary로 만들면 해결됨을 알게 되었다!!!
dictionary자료형은 key와 value로 이루어져 있고 key의 순서는 상관이 없다. 그리고 key는 tuple로 쓸 수 있다. 그러면, 순서를 매길 수 없는 수많은 state tuples를 key로 지정하고 그에 따른 Q-value를 value값으로 지정함으로써 Q-table을 만들고 쓸 수 있다.

Q-table 초기화
어떻게 초기화를 할까? 조르디교수의 MC prediction 내용 설명 중에서 알 수 있었다.

defaultdict(lamda: 0)를 통해서 미리 지정하지 않은 key를 새롭게 집어넣을 수 있고(코딩장이 블로그. dictionaries의 초기화, defaultdict 설명글 참고) 그 key의 value를 0로 지정한다.
그런데 사진의 코드에서는 env.action_space.n이 들어가 있다.
이를 알기 위해서 딥마인드OpenaiGym에서 Blackjack-v0 원본코드를 확인하였다. 잘모르겠다.
그냥 바로 google colab에서 코드를 실행해보았다. 아래처럼 2를 나타냄을 볼 수 있다.

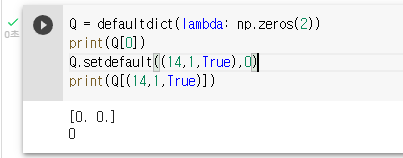
아래처럼 Q-table을 defaultdict함수(from collections import defaultdict 필요)를 사용해 2열(하나는 key, 나머지 하나는 value), 0으로 초기화를 한다.
그리고 setdefault(key, value)로 값을 집어넣는다.
Return-table 만들기
Q-table을 dictionary로 만든 것 처럼, Return-table역시 dictionary로 만든다.
각각의 에피소드에서 얻은 (state, action)에서의 Return값(G)을 저장할 것이다.
즉,
key value
(state,action) [G_1, G_2, ...]
수많은 에피소드(10000회)를 거치고 나면 (state, action) key에는 [G_1, G_2, G_3, G_4, G_5, ..., G_10000]가 생기고
그리고 나면 이 list의 값들의 평균을 Q-table의 value로 update할 것이다.
코드작성
참고코드
2. Deep-Reinforcement-Learning-Explained/DRL_13_Monte_Carlo.ipynb
'기계공학부 시절의 기록 > 강화학습일기' 카테고리의 다른 글
| [MC BlackJack 결과 시각화] 학습결과 그래프로 나타내기 (0) | 2021.11.10 |
|---|---|
| [MC Blackjack-최종] 코드작성과 결과코드 및 실행영상 (2) | 2021.11.04 |
| [MC-블랙잭] Monte Carlo에서 Q-table 어떻게 만들어? (1) 튜플 (5) | 2021.11.02 |
| BlackJack Example. Monte Carlo (0) | 2021.10.23 |
| RL homework - MDP #1 Gambler's problem 이해하기 쉬운 코드 (0) | 2021.10.17 |




댓글